-1.png.webp)

インターネットの発展とともに、私たちは日常的にオンラインサービスを利用するようになりました。しかし、それに伴って個人情報の管理やセキュリティに関する課題も増えています。これまでのIDは、企業や政府が管理する「中央集権型ID」が主流でしたが、近年では「分散型ID(DID)」という新しい概念が注目を集めています。
本記事では、DIDの基本概念から、従来型IDとの違い、具体的なメリット・デメリット、そして将来性までを詳しく解説します。
分散型ID(DID)とは?

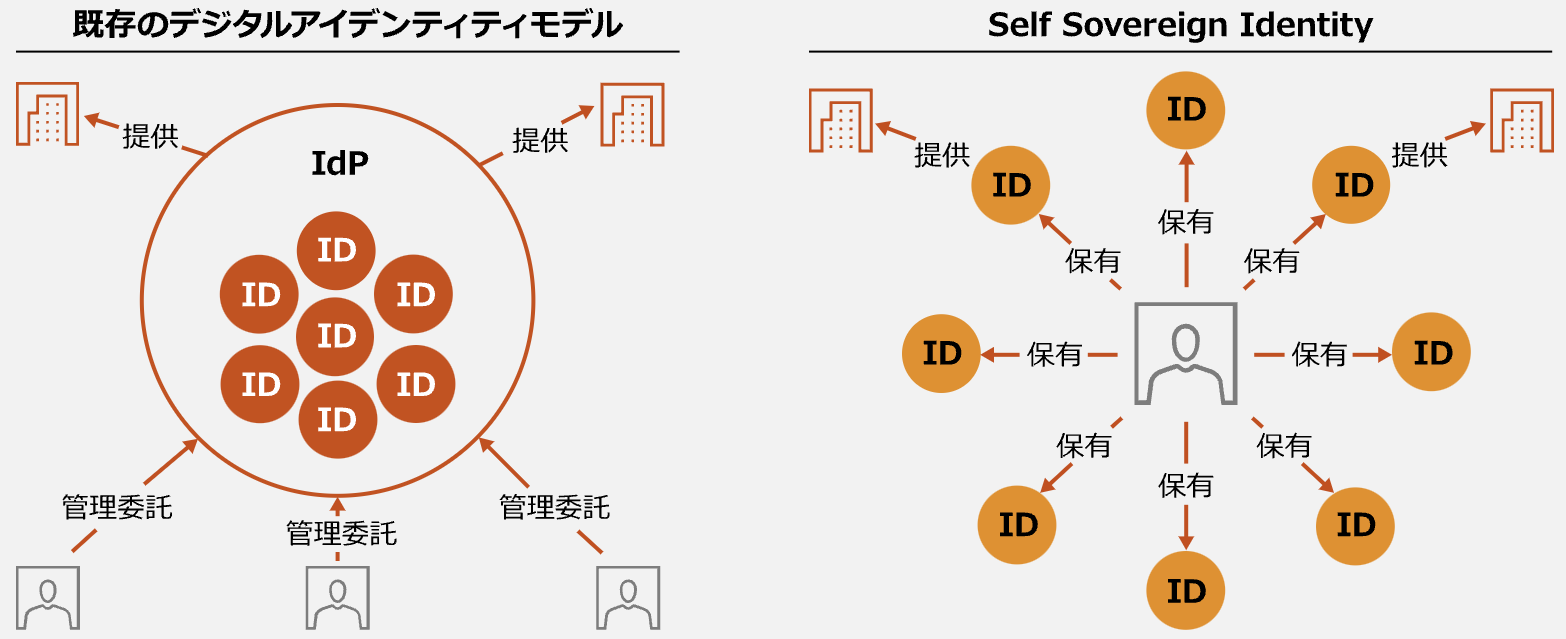
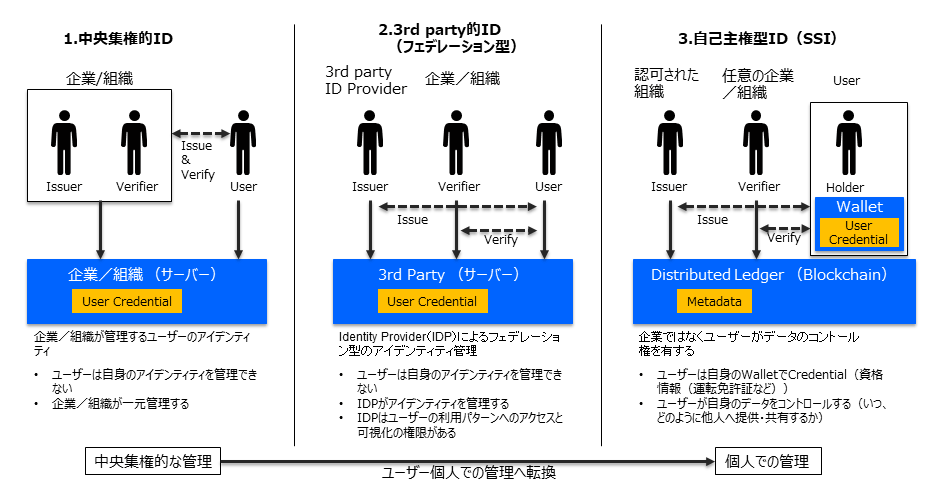
分散型ID(DID)は、近年注目されている新しいID管理の概念です。従来の中央集権型IDとは異なり、DIDは個人が自らのデジタルIDを管理できる仕組みを持っています。この違いを明確にするため、まずは「中央集権型ID」と「分散型ID」の違いを詳しく見ていきましょう。
従来型のIDは中央集権型ID
これまでのID管理は、企業や政府が一元的に管理する「中央集権型ID」が主流でした。例えば、GoogleやFacebookのアカウント、あるいは運転免許証やパスポートなどの公的なIDも、この中央集権型の仕組みによって管理されています。この方式には利便性がある一方で、いくつかの深刻な課題も存在します。
まず、中央集権型IDはデータが特定の管理主体に集中しているため、不正アクセスのリスクが高まります。一度ハッキングが成功すると、芋づる式にすべてのデータが流出する可能性があり、攻撃者にとって魅力的なターゲットとなりやすいのです。企業や政府がセキュリティ対策を講じていたとしても、過去には大手企業のサーバーが攻撃され、大量の個人情報が流出する事件が何度も発生しています。
次に、本人確認(KYC:Know Your Customer)のプロセスにおいて、運転免許証やパスポートなどの中央集権型IDを提出する際、利用者は必要以上の個人情報を開示してしまうという問題もあります。年齢確認が必要なサービスを利用する場合、本来なら「18歳以上である」という事実だけを証明すればよいはずです。しかし、実際には名前や住所、顔写真といった不要な個人情報まで開示しなければならないケースが多く、プライバシーリスクが発生します。
さらに、中央集権型IDでは、複数のサービスを利用する場合、それぞれのID管理主体ごとに異なるIDを発行してもらう必要があり、ユーザーは複数のアカウントやパスワードを管理しなければなりません。この結果、パスワードの使い回しや管理ミスによるセキュリティ事故のリスクが高まります。近年では、IDとパスワードを一度入力するだけで複数のサービスにログインして利用できるシングルサインオン(SSO)などの技術も発展していますが、結局のところGoogleやAppleなど特定の企業に依存する形となり、根本的な解決にはなっていません。
このような問題を解決するために、近年注目を集めているのが「分散型ID(DID)」の概念です。
分散型ID(DID)=自分自身でコントロールできるID
実現手段としてのDID」
分散型ID(DID)とは、「Decentralized Identifier」の略で、日本語では「分散型識別子」を意味します。これは、中央集権的なID管理の課題を解決するために生まれた新しい概念であり、ユーザー自身が自らのデジタルアイデンティティを管理できるIDのことを指します。
DIDは元々、Web技術の標準化団体であるW3C(World Wide Web Consortium)が2022年に勧告した標準規格であり、認証情報の管理を特定のIDプロバイダー(IdP)に依存せず、サービスを利用するユーザー自身がコントロールできるようにすることを目的としています。したがって、従来の中央集権型IDの課題であった情報漏えいやプライバシーの過剰な開示といった問題が解決されると期待されています。
定義だけでは具体的な姿をイメージしづらいですが、DIDの核心にあるのは「SSI(自己主権型アイデンティティ:Self-Sovereign Identity)」という概念です。これは、「個人情報は個人自身が管理し、必要なときに必要な情報のみを開示すべきである」という考え方を基盤とするものです。DIDは、このSSIを技術的に実現するための手段のひとつと考えれば良いでしょう。
また、DIDの特徴のひとつに、「発行主体が存在しない」点が挙げられます。従来のIDは、政府や企業といった特定の機関が発行・管理するものでしたが、DIDはそうした中央管理者を必要とせず、個人が自分自身で識別子を生成・管理できます。そのため、サービス提供者に依存することなく、IDを自由に運用できるのです。
なお、DIDという用語は、時として「Decentralized Identity(分散型アイデンティティ)」の略称として使用されることがあります。「Decentralized Identifier」は特定の技術を指す用語ですが、「Decentralized Identity」は「特定のIdPに依存しないデジタルアイデンティティ管理の考え方そのもの」を指します。基本的には文脈でどちらの概念を指しているのかを判断する必要がありますが、この混乱を避けるために、「Decentralized Identifier」を「DIDs」と表記することもあります。
分散型IDの仕組みをより深く理解するために、次のセクションでは、その技術的な詳細について解説していきます。
分散型ID(DID)の仕組み
DIDは単なる識別子ではなく、それに紐づくDIDドキュメントと密接に関係しています。DIDを利用することで、個人や組織は独自の識別子を作成し、それを用いて信頼できるデジタルアイデンティティを確立できるのです。ここからは、こうしたDIDの基本構造、DIDドキュメントとの関係、そしてDIDの解決プロセスについて詳しく解説していきます。
DIDの基本構造
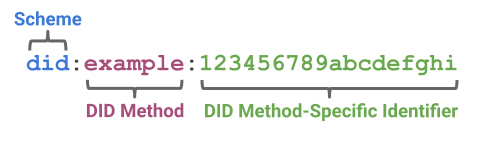
DIDは特定のルールに基づいた文字列で構成されており、「スキーマ」「DIDメソッド」「DIDメソッド固有の識別子」の3つの要素から成り立っています。
まず、スキーマはDIDであることを示す文字列であり、すべてのDIDは共通して「did:」という接頭辞から始まります。これは、W3Cが定める「DID Syntax ABNF Rules」に則った形式で記述されます。
次に、DIDメソッドは、DIDがどの基盤(レジストリ)に登録され、どのように生成・管理されるのかを定義する文字列です。W3Cの要件に基づいて開発者が独自にDIDメソッドを作成できるため、現在では多くの種類のDIDメソッドが存在します。例えば、Bitcoinをレジストリとして利用する「did:ion」や、Ethereumを活用する「did:ethr」、Webサイトのドメインを基にする「did:web」などが代表的なものとして挙げられます。ただし、DIDメソッドは相互運用性を持たないため、一度発行したDIDを別のDIDメソッドに移行することはできません。
最後に、DIDメソッド固有の識別子は、各DIDメソッド内で一意となるものであり、どのように発行されるかはメソッドごとに異なります。例えば、「did:ethr」の場合はEthereumアドレスを基にした識別子が生成され、「did:web」ではWebドメインが識別子として使用されます。
具体的な情報取得の流れ
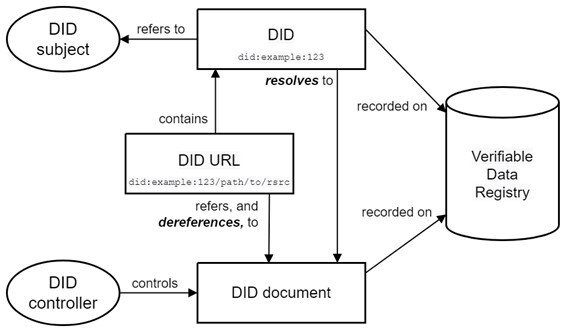
上図はW3Cが提唱するDIDのアーキテクチャの概念図です。DIDエコシステムにおける各コンポーネントの役割は以下の通りです。
- DIDサブジェクト:DIDの所有者(例:個人、企業、IoTデバイスなど)。
- DIDドキュメント:DIDに関連するデータを格納するドキュメントで、DID自身の情報や公開鍵などが記載されている。
- DIDコントローラー:DIDドキュメントを更新・削除する権限を持つ主体。多くの場合、DIDサブジェクトと同一だが、異なる場合もある。
- DID URL:DIDにパスやクエリパラメータを追加したもので、DIDドキュメント内の特定の情報(例:公開鍵)を指し示すために使用される。
- 検証可能データレジストリ:DIDとDIDドキュメントが保存される場所。多くの場合、ブロックチェーンや分散型台帳が利用される。
DIDは、所有者情報や公開鍵の情報などを格納したDIDドキュメントと一対一で対応しており、DIDを利用するためには、DIDを解決(resolve)することでDIDドキュメントを取得する必要があります。DIDの解決プロセスは、以下のように進行します。
- DIDの指定
まず、ユーザーは解決したいDIDを指定します。例えば、「did:example:123456789abcdef」といった形式のDIDを入力し、リゾルバ(DID解決ツール)に対してDIDの解決を要求します。 - DIDメソッドの特定
次に、DIDのスキーマ部分を解析し、使用されているDIDメソッドを特定します。各DIDメソッドは、それに対応するDIDドキュメントの取得方法を持っています。DIDメソッドによって、データの保存場所(ブロックチェーン、IPFS、Webサーバーなど)や、DIDの生成・管理方法が異なります。 - DIDドキュメントの取得
DIDメソッドが特定されたら、リゾルバはそのメソッドに適したプロトコルを使用してDIDドキュメントを取得します。DIDドキュメントは通常、分散型台帳(ブロックチェーン)、IPFS、もしくはDIDメソッドによって指定されたストレージに格納されています。例えば、「did:web」の場合はWebサーバーからDIDドキュメントを取得し、「did:ethr」の場合はEthereumのブロックチェーンから取得します。 - DIDドキュメントの検証
取得したDIDドキュメントが改ざんされていないかを確認するため、デジタル署名を検証します。DIDドキュメントには、所有者の公開鍵や署名情報が含まれているため、リゾルバはそれらの情報を用いてドキュメントの正当性をチェックします。これにより、不正に改ざんされたDIDドキュメントを排除し、信頼性のある認証を実現できます。
公開鍵暗号方式とは?
公開鍵暗号方式とは、情報を通信する際に、送信者が誰でも利用可能な公開鍵を使用して暗号化を行い、受信者が秘密鍵を用いて暗号化されたデータを復号化するという手法のこと。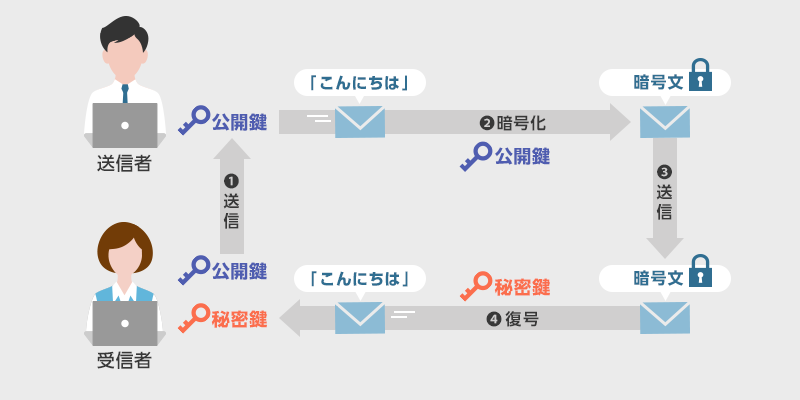
秘密鍵は特定のユーザーのみが保有する鍵で、この秘密鍵から公開鍵を生成することは可能。しかし、公開鍵から秘密鍵を特定することは現実的には不可能。公開鍵で暗号化されたデータは対応する秘密鍵でしか復号化できないため、秘密鍵さえ厳重に管理していれば、データの保護と情報漏洩の防止が可能となる。
分散型ID(DID)のメリット

分散型ID(DID)は、従来の中央集権型IDの課題を解決する技術として注目されていますが、その大きな利点は、セキュリティとプライバシーの向上、ユーザー自身によるID管理の強化、そしてオンライン認証の利便性の向上にあります。以下では、DIDがもたらす主なメリットについて詳しく説明します。
情報漏えいのリスクが低い
DIDは、リスが餌のなくなる冬に備えて食料を複数の場所に分散して隠す「貯食」とよばれる習性に似ています。巣穴など一箇所に全ての食料を蓄えた場合、もし巣が天敵に襲われたり、災害に見舞われたりすると、全ての食料を失ってしまいますが、分散して食料を埋めておけば一つの隠し場所が失われても、他の場所に隠した食料は無事です。
同様に、従来のID管理システムでは、一箇所のサーバーに大量の個人データが集約されているため、サーバーが「単一障害点」となり、ここが攻撃を受けるとシステム全体が停止したり、多くのユーザーの情報が一括して流出するリスクがありました。実際、大量の顧客情報が流出して企業の役員陣が謝罪会見を開く、という光景も現代では珍しいことではないかと思います。
一方で、DIDは中央管理者を介さずにユーザーが自身のIDを管理するため、単一障害点が存在しません。もし一部のノードが攻撃を受けても、他のノードは正常に稼働し続けるため、システム全体が停止するリスクを軽減できます。したがって、ハッキングのハードルも高く、芋づる式に個人情報が流出するリスクを最小限にできるのです。
このように、DIDは「情報セキュリティ」という観点において、中央集権的なID管理システムが抱える脆弱性を克服し、より安全で堅牢なID管理を実現するための有効な手段となり得るでしょう。
小見出し:必要最小限の情報提供で認証が可能
私たちが居酒屋などでアルコール類を注文する際、「20歳以上であること」を証明するために身分証明書を提示することが求められることがあります。しかし、これらの身分証には名前や住所、顔写真といった本来不要な情報まで含まれています。実際に相手が確認したいのは「この人が法律上、飲酒が可能な年齢かどうか」だけのはずが、不要な個人情報まで開示してしまうのです。
DIDがあれば、こうした過剰な情報開示を防ぐことができます。「この人が20歳以上である」という事実だけを証明し、それ以外の個人情報を一切見せることなく、年齢確認を完了できるのです。これにより、身分証を提示するたびに不必要な情報まで渡してしまうリスクを軽減できます。
この仕組みを可能にするのが、「ゼロ知識証明(Zero-Knowledge Proof)」と呼ばれる暗号技術です。ゼロ知識証明とは、「ある事実が正しいことを証明する際に、その根拠となるいかなる情報も明かさずに済む」仕組みです。
少し難しい概念であるため、本格的にゼロ知識証明を理解したい方は、以下の米国カリフォルニア大学ロサンゼルス校(UCLA)のAmit Sahai教授の解説動画を参考にすると良いでしょう。
このように、DIDは単なる認証技術ではなく、「プライバシーを守りながら、必要な情報のみを適切に提供できる新しいデジタルアイデンティティ管理の枠組み」として、今後ますます重要な役割を果たすと考えられています。
ID管理が簡素化される
日常的に使うオンラインサービスが増えるにつれ、私たちは多くのアカウントを管理しなければならなくなっています。SNS、ネット通販、銀行、サブスクリプションサービスなど、それぞれのサービスで異なるIDとパスワードを設定し、覚えておくのは非常に手間がかかります。パスワードを忘れればリセット手続きを行う必要があり、煩雑な手間がかかるだけでなく、パスワードの使い回しによるセキュリティリスクも高まります。
DIDは、特定の企業や組織に依存せずにユーザー自身がIDを管理できる仕組みを提供し、ID管理の負担を大幅に軽減できます。例えば、DIDをデジタルウォレットに保存しておけば、各サービスごとに異なるIDやパスワードを覚えておく必要はなく、DIDを使ってシームレスにログインが可能になります。従来の「IDとパスワードを入力する」というプロセスを省略し、より直感的でスムーズな認証体験を実現できるのです。
「ソーシャルログインでいいのでは?」 と思われる方もいるかもしれません。確かに、GoogleやFacebookなどのアカウントを利用したソーシャルログインは便利です。しかし、これらのサービスはあくまで中央集権的なプラットフォームに依存しています。つまり、これらのプラットフォームがサービスを停止したり、アカウントが乗っ取られたりした場合、利用者はサービスにアクセスできなくなる可能性があるのです。
一方、DIDは分散型のID管理システムであり、特定のプラットフォームに依存しません。ユーザーは自身のDIDを完全にコントロールでき、プラットフォームの都合に左右されることなく、様々なサービスにアクセスできます。
このように、DIDの導入によって、ユーザーはパスワード管理の煩わしさから解放され、企業側もセキュリティ対策の負担を軽減できます。こうしたシンプルかつ安全なID管理も、DIDのメリットの一つといえるでしょう。
見出し:分散型ID(DID)のデメリット

DIDは多くのメリットをもたらしますが、一方でいくつかの課題も抱えています。特に管理の責任がすべてユーザーに委ねられることや標準化という問題は、DIDの普及に向けた大きなハードルとなっています。順番に解説します。
管理リスクとユーザー責任
中央集権型のID管理システムでは、パスワードを忘れた場合でも、運営元に問い合わせればリセット手続きを行うことができます。しかし、DIDでは話が違います。DIDの認証には秘密鍵が不可欠であり、その秘密鍵の管理は完全にユーザーの責任となります。もし秘密鍵を紛失すると、アカウントを復旧する手段はほぼ存在せず、DIDに紐づいたデータや権利をすべて失う可能性があります。
これは、同じく分散型管理を行っている暗号資産(仮想通貨)のウォレットの秘密鍵を紛失した場合に似ています。 例えば、ビットコインを保有している人が秘密鍵を紛失した場合、どれほど多額のビットコインを保有していても、誰もアクセスすることができなくなります。銀行口座の暗証番号を忘れた場合とは異なり、ビットコインの場合は、秘密鍵が唯一のアクセス手段であるため、紛失は即座に資産の喪失に繋がります。
「ビットコイン2億ドル以上」の資産、パスワード紛失でアクセス不可に | Forbes JAPAN 公式サイト(フォーブス ジャパン)
DIDも同様であり、秘密鍵を失えばIDそのものが無効になり、再発行も難しくなります。
また、セキュリティの観点からも、従来のID管理よりも慎重な運用が求められます。例えば、秘密鍵を適切に保管するためには、ハードウェアウォレットやオフライン環境での管理が推奨されますが、これは一般ユーザーにとってはハードルが高いでしょう。従来の「パスワード管理が面倒」という問題から解放される一方で、「秘密鍵の管理が厳格であるべき」という新たな課題が発生するのです。
こうしたリスクに対処するため、現在、業界ではいくつかの解決策が検討されています。「ソーシャルリカバリー」という仕組みでは、ユーザーが信頼できる複数のコンタクト(友人や家族、企業)を「回復代理人」として登録し、秘密鍵を失った際に彼らの承認を得ることで復旧が可能です。
すでにEthereumのウォレット「Argent」などではこの手法が採用されており、DIDにおいても類似の仕組みが導入されつつあります。このような技術が進展すれば、秘密鍵の紛失によるリスクは大幅に軽減されるでしょう。
標準化の遅れや普及の課題
DIDは中央管理者に依存しない仕組みを実現していますが、それゆえに標準化の遅れや相互運用性の問題が生じています。現在、W3CによってDID全般の基本仕様は定義されているものの、特定のDIDメソッドを標準化しているわけではありません。そのため、各サービスにおいて独自のDIDメソッドが開発されており、異なるDIDメソッド間での互換性が十分に確立されていません。
このような相互運用性の問題は、DIDの普及を妨げるだけでなく、利用者側の混乱を招く可能性もあります。どのメソッドでDIDを取得すればよいのか、どのサービスでどのメソッドが利用できるのか、といった情報が分かりにくく、DIDの利用をためらう要因となっています。
しかし、こうした課題に対処するため、すでに業界ではDIDメソッドごとの違いを吸収し、異なるメソッド間でもスムーズにDIDを利用できるようにする技術開発が行われており、Microsoft、IBM、Hyperledgerといった企業もこの分野に積極的に参画しています。
また、普及の観点では、すでに一部の行政サービスや金融機関がDIDを活用した実証実験を開始しています。欧州連合(EU)は「European Self-Sovereign Identity Framework(ESSIF)」を推進し、DIDを活用したデジタルアイデンティティの構築を進めており、日本でも地方自治体や民間企業がDIDを活用した本人確認の仕組みを試験的に導入する動きがあり、今後の展開が期待されています。
こうした標準化の進展や企業・政府の取り組みが加速すれば、DIDの相互運用性の課題は徐々に解決し、より多くの場面で実用化が進むことが予想されます。DIDが普及することで、私たちはより安全で便利なデジタル社会を実現できる可能性があります。
分散型ID(DID)とブロックチェーンとの関連性

これまで見てきたように、分散型ID(DID)は従来の中央集権型ID管理の課題を解決する新しい仕組みとして注目されています。しかし、DIDが安全かつ分散的に機能するためには、そのデータをどこに記録し、どのように管理するかが重要なポイントとなります。その解決策の一つとして活用されているのが「ブロックチェーン」です。DIDとブロックチェーンはどのように関連しているのか、その理由を解説していきます。
ブロックチェーンとは?
ブロックチェーンは、サトシ・ナカモトと名乗る人物が2008年に発表した暗号資産「ビットコイン」の中核技術として誕生しました。ブロックチェーンの定義には様々なものがありますが、噛み砕いていうと、「取引データを暗号技術によってブロックという単位にまとめ、それらを鎖のようにつなげることで正確な取引履歴を維持する技術」です。
ブロックチェーンはデータベースの一種ですが、そのデータ管理方法は従来のデータベースとは大きく異なります。従来の中央集権的なデータベースでは、全てのデータが中央のサーバーに保存されるため、サーバー障害やハッキングに弱いという課題がありました。
一方、ブロックチェーンはネットワークに参加する各コンピュータ(ノード)がデータのコピーを持ち、分散して保存します。そのため、サーバー障害が起こりにくく、ハッキングにも強いシステムだといえるでしょう。
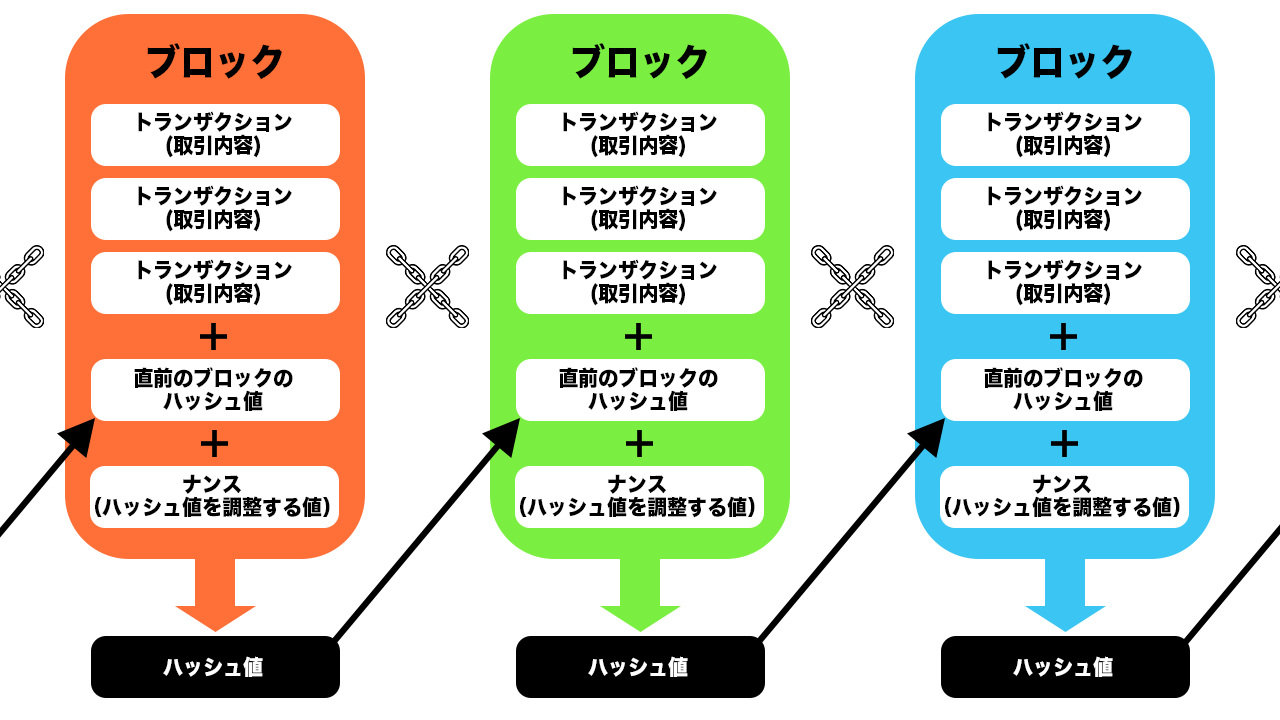
また、ブロックチェーンでは、ハッシュ値と呼ばれる関数によっても高いセキュリティ性能を実現しています。ハッシュ値とは、あるデータをハッシュ関数というアルゴリズムによって変換した不規則な文字列のことで、データが少しでも変わると全く異なるハッシュ値が生成されます。新しいブロックを生成する際には必ず前のブロックのハッシュ値が記録されるため、誰かが改ざんを試みると、それ以降のブロックのハッシュ値を全て再計算する必要があり、改ざんが非常に困難な仕組みとなっています。
さらに、ブロックチェーンでは、マイニングという作業を通じて取引情報のチェックと承認を行う仕組み(コンセンサスアルゴリズム)を持っています。マイニングとは、コンピュータを使ってハッシュ関数にランダムな値を代入する計算を繰り返し、ある特定の条件を満たす正しい値(ナンス)を見つけ出す作業のことです。
最初にマイニングに成功した人に新しいブロックを追加する権利と報酬が与えられるため、この報酬がネットワークの維持に貢献するインセンティブとなり、ブロックチェーンエコシステム全体の安定性を支えています。
このように、ブロックチェーンは分散管理、ハッシュ値、マイニングなどの技術を組み合わせることで、データの改ざんや消失に対する高い耐性を持ち、管理者不在でもデータが共有できる仕組みを実現しています。
詳しくは以下の記事でも解説しています。
なぜブロックチェーンがDIDのレジストリに適している?
技術の最新動向」
DIDの概念を技術的に支えるためには、そのID情報を安全かつ分散的に保存する必要があります。ブロックチェーンは、その特性上、DIDのレジストリとして非常に適した技術の一つとされています。
自己主権型アイデンティティ(SSI)では、個人が自分のアイデンティティを管理することが求められます。しかし、デジタルID保有者が虚偽の情報を登録したり、資格を偽造したりするリスクがあるため、透明性と改ざん耐性が求められます。ここで、分散台帳技術(DLT)や公開鍵暗号など、ブロックチェーンの技術が活用されることで、デジタルIDの信頼性を向上させることができます。
また、DIDを管理するデータベースは特定のサービス事業者や中央機関に依存しないことが重要です。ブロックチェーンのノードは分散的に運営され、単一の管理者が存在しないため、特定の企業や政府がDIDを恣意的に管理することができません。特に、パブリックブロックチェーンは中央集権的な機関に依存せずに運用できるため、DIDの基盤として適していると考えられています。
ただし、DIDのレジストリとして必ずしもブロックチェーンが唯一の選択肢というわけではありません。DIDの仕様上、ブロックチェーン以外の分散台帳技術やその他のデータ管理手法を用いることも可能であり、今後さらなる技術革新が進むことで、より柔軟なDID管理の方法が登場する可能性もあります。
ですが、ブロックチェーンに記録されたIDは、他者によって勝手に更新・削除されることがないという類を見ない特徴があり、この点が、ユーザー自身がIDの生成・更新・削除を行うという自己主権型アイデンティティの思想と相性が良いということも相まり、ブロックチェーンがDIDの基盤としてファーストチョイスであるという構図は大きくは変わらないでしょう。
分散型ID(DID)とVCs(Verifiable Credentials)との関連性

デジタルアイデンティティを管理する際、DIDだけでは十分ではありません。DIDはあくまで「識別子」であり、そこに資格や証明書といった追加情報を付与することで、オンライン上での信頼性を確立できます。その役割を担うのが「VCs(Verifiable Credentials)」です。DIDとVCsの関係を理解することで、より実践的なデジタルアイデンティティ管理の仕組みが見えてきます。
VCs(Verifiable Credentials)とは?
VCsとは「Verifiable Credentials」の略であり、日本語では「検証可能な資格証明」と訳されます。具体的には、個人が所有できるデジタル上の証明書でありながら、その正当性については信頼できる第三者機関によって検証される仕組みを指します。
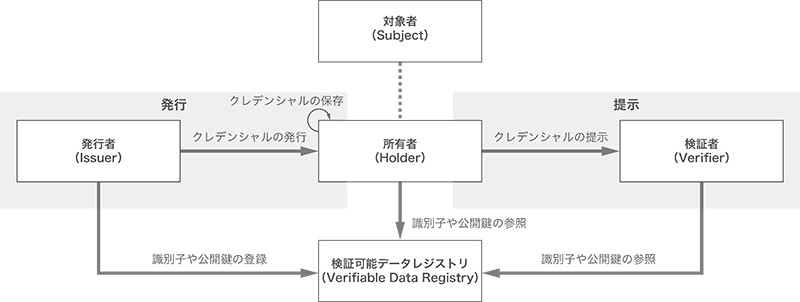
VC(個々の資格証明の流れについて見ていく場合はVCと略します)は、主に次の4要素で構成されています。
- 発行者(issuer):VCを発行する者
- 所有者(holder):VCを発行者から取得し、保有・利用する者
- 検証者(verifier):保有者が提示したVCが信頼できるものであるかを検証する者
- レジストリ(Registry):分散型台帳やブロックチェーンといった各種データベース
VCはまず発行者によって発行がなされます。この発行者は、運転免許証であれば都道府県公安委員会、学歴証明書であれば国立大学法人や学校法人、健康診断結果であれば医療機関などが該当します。発行時には暗号技術の仕組みを利用してVCにデジタル署名を付与し、復号に必要な鍵(公開鍵)は改ざんができない仕組みを持つレジストリに登録します。
次に、所有者は発行者から受け取ったVCをデジタルウォレットと呼ばれる保管場所に格納し、必要に応じて利用します。利用の際には、VCをそのまま検証者に提示するのではなく、VP(Verifiable Presentation)という提示用のフォーマットに変換したものを提示します。
検証者は、所有者からVPの提示を受けた後、レジストリに登録されている発行者の公開鍵を使ってVPを検証し、デジタル証明書の信頼性を確認します。そして、その検証結果に応じてサービスの提供の可否を判断したり、提供プランを変更したりすることができます。
VCsを活用することにより、不透明な情報の可視化や真偽の疑わしい情報を公正に検証することが可能になり、デジタル上で個人情報を様々なサービスで利用できるでしょう。こうした可視化できない個人情報を証明する仕組みは、企業だけでなく行政や医療機関なども注目しており、VCsに関する取り組みは今後さらに活発になっていくものと考えられます。
DIDは「誰」かを証明し、VCsは「どのような資格や権利を持っているか」を証明する
ここまでの説明を聞くと、DIDとVCsは共に個人情報を安全に管理し、プライバシーを保護するための技術であり、デジタルアイデンティティを構成する上で重要な役割を果たしていることは理解できたかと思います。しかし、「結局DIDとVCsはどう違うのか?」という点が、まだはっきりしないと感じる方も少なくないのではないでしょうか?
両者の違いを簡単に説明すると、「DIDはあなたが誰であるかを証明し、VCsはあなたがどのような資格や権利を持つ人物なのかを証明するもの」です。イメージしやすい例として、「学生証(≒DID)」と「成績証明書(≒VCs)」を考えてみましょう。
学生証は、あなたがその大学に在籍している学生であることを証明するものです。学生証には、あなたの名前や学籍番号、顔写真などが記載されており、あなたが確かにその大学の学生であることを示します。これはまさにDIDの役割であり、「あなたが誰であるか」を証明するものです。
学生証だけでは、「学生である」という情報以外の情報は分かりません。学割の適用や単なる年齢確認であればそれだけでも問題ないですが、例えば採用面接など、その人の内面や能力を推し量る指標としては不十分です。
一方、成績証明書は、あなたがどのような授業を履修し、どのような成績を修めたかを証明するものです。成績証明書には、あなたの名前や学生番号、履修した授業科目名、成績などが記載されており、あなたがどのような学習成果を上げたかを具体的に示します。これはVCsの役割であり、「あなたがどのような資格や権利を持つ人物なのか」を証明するものです。
しかし、成績証明書だけには氏名や学生番号が記載されているものの、それが本当に本人のものかどうかを証明する手段はありません。顔写真がついている学生証と学習の履歴が記載されている成績証明書が組み合わさることで初めて、あなたが確かにその大学の学生であり、特定の授業を履修し、一定の成績を修めた人物であることを証明できるのです。
同様に、DID単体では身元の証明以外にはあまり役に立たず、VCsと組み合わせることで初めて信頼性と利用可能性のあるアイデンティティを確立できます。つまり、DIDは識別子としての役割を担い、VCsはその識別子に対して意味を付与するものだと考えると分かりやすいでしょう。
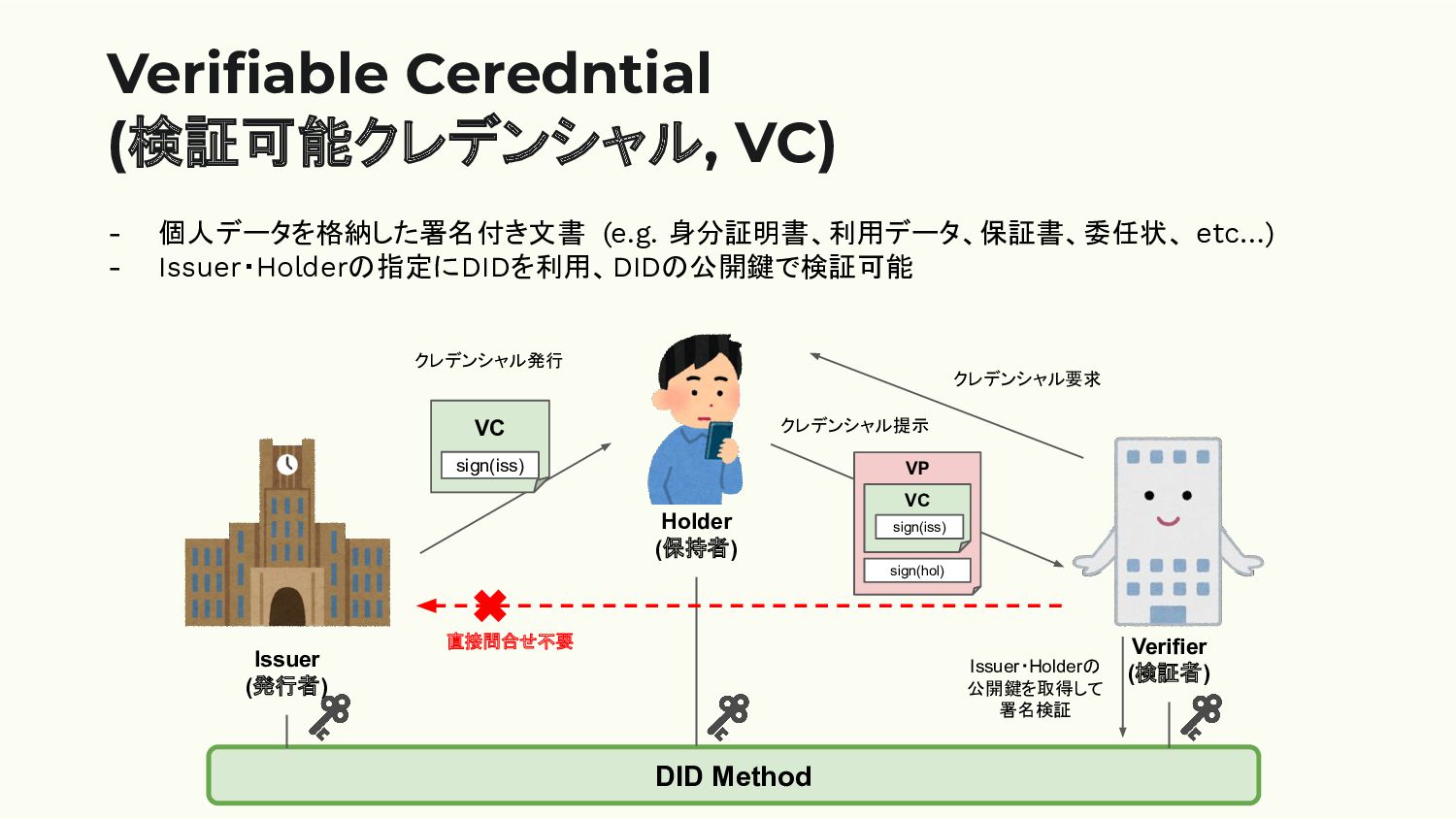
また、DIDとVCsを連携させれば、「発行者(Issuer)」と「検証者(Verifier)」が直接コミュニケーションを取る必要もなくなります。従来、企業が応募者の学歴を確認する際、大学に直接問い合わせるケースがありました。しかし、この方法では大学側に負担がかかるだけでなく、確認に時間がかかるというデメリットもありました。そのため、企業が確認作業を省略してしまい、結果的に学歴詐称が発生することもあります。
他方、VCsには発行者のDIDが紐付けられており、公開鍵によってデジタル署名が検証可能です。そのため、検証者は発行者に直接問い合わせることなく、VCsのデータが改ざんされていないことを即座に確認できます。これは、本人確認の精度を高めるだけでなく、手続きの効率化にもつながります。
このように、DIDとVCsを組み合わせることで、オンライン上でも信頼性の高いデジタルアイデンティティを構築できます。中央集権的な認証システムに頼ることなく、ユーザー自身がデータを管理し、必要な情報を必要な範囲で提供できるという点で、DIDとVCsはデジタル社会の新たなインフラとして重要な役割を担っていくでしょう。
VCsについては以下の記事でも詳しく解説しています。
分散型ID(DID)の市場規模とは?

これまで見てきたように、DIDは従来の中央集権型ID管理が抱える課題を解決する新しい仕組みとして注目されています。セキュリティの強化、プライバシー保護の向上、そしてユーザーが自身のIDをコントロールできる点が大きな魅力となり、さまざまな業界で導入の動きが進んでいます。こうした背景を受け、DID市場は急速に成長しつつあります。
株式会社グローバルインフォメーションのレポートによると、DID市場の規模は2024年時点で11億5,300万米ドルに達しており、2033年には896億2,800万米ドルにまで拡大すると予測されています。この成長率は年平均62.2%という非常に高い数値であり、DIDが今後のデジタルアイデンティティ管理において重要な役割を果たしていくことを示しています。
DID市場の拡大を支える要因の一つが、個人データの管理と所有権に対する意識の高まりです。GAFA(Google、Apple、Facebook、Amazon)をはじめとする企業が収集・管理する個人データの量は年々増加しており、ユーザーの間では「自分のデータを自分で管理したい」というニーズが強まっています。データ漏えいや不正利用が頻発する中で、企業や政府による一元管理のリスクを回避し、ユーザー自身が情報の開示範囲をコントロールできるDIDへの関心が高まっているのです。
また、オンライン上で共有される個人情報の増加も、DID市場を後押しする要因となっています。従来の認証システムでは、IDプロバイダーがユーザーの情報を管理し、サービスごとに個人情報を提供する必要がありました。しかし、その反面でサイバー攻撃やデータ侵害の標的になりやすく、特に金融機関や医療機関など、高度なセキュリティが求められる業界では深刻な問題となっています。DIDを活用すれば、第三者を介さずに安全な認証が可能となり、こうしたリスクを低減できます。そのため、ヘルスケアや消費財、製造業、小売業など、多様な業界でDIDを活用したソリューションの導入が進んでいます。
さらに、技術の進化もDID市場の成長を支えています。人工知能(AI)や機械学習(ML)、モノのインターネット(IoT)といった分野では、DIDと組み合わせることでより高度な認証技術が実現可能になります。例えば、IoTデバイスがDIDを活用することで、安全なネットワーク環境を構築し、スマートホームや自動運転車などの分野でのセキュリティ強化が期待できます。
このように、DID市場の拡大は、デジタル社会の在り方そのものを変える可能性を秘めています。これまでは個人情報は企業や政府が一括して管理するのが当たり前でしたが、DIDの普及により「自分のデータは自分で守る」という新しい概念が一般化していくのかもしれませんね。
まとめ
本記事では分散型ID(DID)について解説しました。
DIDは、ユーザー自身がデジタルアイデンティティを管理することで、従来の中央集権型ID管理が抱えていたセキュリティリスクやプライバシー問題を解決する画期的な技術である一方、標準化の遅れや秘密鍵の管理といった課題も存在しており、技術的な発展とともに、実用化に向けた環境整備が求められています。
DIDの技術的な進化や法整備の進展とともに、今後の市場の成長がどのように進んでいくのか、引き続き注目する価値があるでしょう。
トレードログ株式会社は、非金融分野におけるブロックチェーン開発に特化しており、システム設計やコンサルティングを提供する企業です。 これまでの豊富な開発実績を活かし、貴社の課題に合わせたブロックチェーン活用の最適なアプローチをご提案いたします。
「ブロックチェーンを自社のビジネスにどう活かせるの?」
「ブロックチェーン技術を導入したいが、何から始めればいいの?」
こうしたお悩みをお持ちの企業様は、ぜひ当社までお気軽にお問い合わせください。 貴社のビジネスにブロックチェーンを活用するための第一歩を、共に踏み出しましょう。