

IoT、ブロックチェーン、AI。一見、無関係にもみえるこれらの概念は、実は、「ビッグデータを活用したDX」という文脈で相互補完的な役割を果たしています。そのなかでもブロックチェーンは、特に不可欠な存在です。今回は初心者向けにざっくりと解説します!
これだけは押さえたい!IoT、ブロックチェーン、AIの基礎知識
IoT、ブロックチェーン、AI(人工知能)は、最近よく話題に上がる技術ですが、それぞれが何を意味するのか、イメージしづらいと感じる人もいるかもしれません。これらは単独でも大きな可能性を秘めていますが、組み合わせることでさらに革新的な展開が期待されています。ここでは、それぞれの基本的な仕組みをわかりやすく紹介していきます。
IoT

IoT(Internet of Things、モノのインターネット)とは、「世の中のあらゆるモノをネットワークに接続することで、さまざまな付加価値を生み出すことを目的としたITインフラストラクチャ(JRIレビュー(北野2017))」を指す言葉とされています。このように定義で説明されても、ほとんどの人(少なくともこの記事に行き着いた人)には「イメージが湧くような?湧かないような?」という感じかもしれません。もう少し具体的に見ていきましょう。
インターネットは、アメリカ国防総省(DoD)が進めた研究プロジェクト「ARPANET」を起源にもっており、アメリカ国内の大学や研究機関を接続し、研究者同士が効率的な情報交換を行うために発達してきたものでした。インターネットの利便性が知られるようになると、これを営利目的に使いたいという要望が強くなり、1990年代に入ると商用インターネットが解禁されました。スマホを含むモバイル端末や、PCを通じて人々の暮らしが圧倒的に便利になる一方で、次第にテレビやカメラ、冷蔵庫やエアコンなど、これまではインターネットに接続されていなかったあらゆる機器にまでネットワークを広げようとする動きが出てきます。この概念が、IoTなのです。最近よく聞く単語の割には中身がスカスカだと拍子抜けするかもしれませんが、だからこそ、結びつくアイデアや活用先次第ではその可能性は無限大なのです。
IoTを理解する上で重要なポイントは次の3点です。
- モノ(デバイス)をインターネットに接続する
- アプリケーションによって付加価値を生み出す
- IT基盤(インフラストラクチャ)である
一般に、IoTと聞いて思いつくのはセンサーで自動的に電気をつけたり音声認識でエアコンをつけたりといった「スマート家電」と呼ばれる領域でしょう。スマート家電では、①もともと独立したモジュールであった電気やエアコンといった端末をインターネットに接続し、②スマホアプリ等を用いて手動で起動する手間を省いたり相互に連動することで住宅の快適さを上げるという付加価値を生み出しています。しかし、こうした典型的なIoT概念で見落としがちなのが、3つ目のポイントです。
実は、「自動的に起動する」「連動する」といったことは、あくまで個人消費者向けの小さなメリットに過ぎません。IoTは、そうした小さな範囲にとどまる概念ではなく、センシング技術を通じて集積したビッグデータをAI(人工知能)やブロックチェーンといった技術とともに利活用することで、経済活動の効率性や生産性を大きく向上させ、さらに高齢・人口減少社会における経済、社会保障などの面で生じる課題を解決する手段としても注目を集める、③社会の基盤そのものに成り代わるような概念なのです。
例えば、家電の域を超えて車両がIoTに対応することで、渋滞情報のリアルタイム共有や路線バスの安定運行、自律走行ロボットを活用した無人配送サービスなど交通インフラを整備することさえ可能です。いわゆる「スマートシティ」と呼ばれる構想です。もちろん、ミクロのIoTも技術的には大変興味深いですが、様々な社会課題解決や新たな社会価値を創出していくために、国民生活や経済行動そのものを変容させ得る可能性を秘めているという点は、IoTを語る上で欠かすことのできない視点といえるでしょう。
AI(人工知能)

近年では、AI(人工知能)の生活への浸透度は非常に高くなっており、身近な製品やサービスで活用されることも珍しくなくなってきました。最たる例はApple社の音声アシスタント「Siri」でしょう。「Hey Siri」とiPhoneに話しかけると起動でき、端末に触れることなく様々な操作をしてくれます。AIについて詳しくない方でも、「AI=便利なもの」という認識はあるはずです。
近年のAIブームを見ていると、つい最近誕生した技術かのように思えますが、AIは1956年にアメリカで開催されたダートマス会議で誕生し、その後はインスタントカメラやルーズソックスなどと同じく、ブーム再燃によって度々脚光を集めてきました。ただし、70年近く前に誕生したとはいっても、何か物理的な完成品が生まれたのではなく、科学者たちが人間のように考える機械を「Artificial Intelligence」と名付けたというだけに過ぎません。そのため、AIという言葉が指す範囲は非常に幅広く、映画「ターミネーター」のような人間を超越しうる存在としてのAI(「強いAI」)から、ビジネスパーソンにおなじみのExcelや電卓(「弱いAI」)まで、およそ人間の知能労働を代替するコンピュータとアルゴリズムが総じてAIと呼ばれているのです。
最初のAIブームはこのダートマス会議の流れを汲んで1950年代に起こりました。この時期の研究は、初期のAI研究者たちが概念的なフレームワークを構築し、人間の思考を模倣するコンピュータープログラムを開発するというものでした。コンピューターを使った論理的な推論自体は実現したものの、基本的には予め特定の問題を解決するための知識をプログラミングする手法をとっていたため、パズルや明確なルールがあるゲーム(トイプロブレム)などには強い一方で、ルールが不明確で複雑な問題を苦手としていました。こうしたアルゴリズムの限界などから期待されたほどの成果が得られず、AIへの関心が下火となりました。
そこから数年は技術の進展が見られず、苦しい時期を過ごしたAI研究ですが、1980年代に入ると再び脚光を浴びるようになります。そのきっかけとなったのが「エキスパートシステム」の実現でした。エキスパートシステムとは、ある分野の専門家の持つ知識をデータ化することで、その分野において人間の専門家に匹敵する知識を持つコンピュータープログラムを開発する手法のことです。それまでのAIに「何でも屋」の役割を要求していた開発手法から脱却することで、医療診断、金融のデータ解析といった限定的な場面でエキスパートシステムが実用的な成果を上げました。ビジネスでの導入例も出現するなど好調に見えた第2次AIブームでしたが、エキスパートシステムは特定のシーンで適用されるには優れていましたが、一般的な知的タスクへの拡張が課題となり、AI研究は再び停滞します。
再び冬の時代に入ったAI業界ですが、2006年にある研究者の発見により転機が訪れます。それが、ジェフリー・ヒントンにより発明された「ディープラーニング」です。ディープラーニングとは、入力データからAI自ら特徴を判別し、特定の知識やパターンを覚えさせることなく学習していくことができる技術のことで、別名「深層学習」とも呼ばれます。こうした技術に加え、マシン性能の向上やインターネットによるデータ収集効率の向上なども相まって過去の一過性のブームとは異なり、AIを私たちの日常生活に深く浸透させる結果を生みました。2022年にOpenAIからChatGPTが発表されると10日足らずでユーザー数が100万人を超え、世間に衝撃を与えたことは記憶に新しいのではないでしょうか。
現時点ではコンピュータの計算能力やデータ自体の精度、機械学習を適切に扱えるデータサイエンティストやビジネスパーソンの存在など、様々なボトルネックが存在していますが、AI研究の第一人者であるレイ・カーツワイル氏は、2029年頃にAIが人間を超えると予測するなど、「シンギュラリティ(技術的特異点)」へ到達する日も遠くないとされており、AIはまだ発展途上にある技術でありながら、社会構造そのものを大きく変える可能性を秘めています。
ブロックチェーン

上記二つの概念と比べるとまだまだ知名度は低いブロックチェーンですが、2008年にサトシ・ナカモトと呼ばれる謎の人物によって提唱された暗号資産「ビットコイン」の中核技術として誕生しました。ブロックチェーンは知らずとも、ビットコインの名前はほとんどの方が一度は聞いたことがあると思います。
ブロックチェーンの定義には様々なものがありますが、噛み砕いていうと「取引データを暗号技術によってブロックという単位でまとめ、それらを1本の鎖のようにつなげることで正確な取引履歴を維持しようとする技術のこと」です。取引データを集積・保管し、必要に応じて取り出せるようなシステムのことを一般に「データベース」といいますが、ブロックチェーンはそんなデータベースの一種でありながら、特にデータ管理手法に関する新しい形式やルールをもった技術となっています。
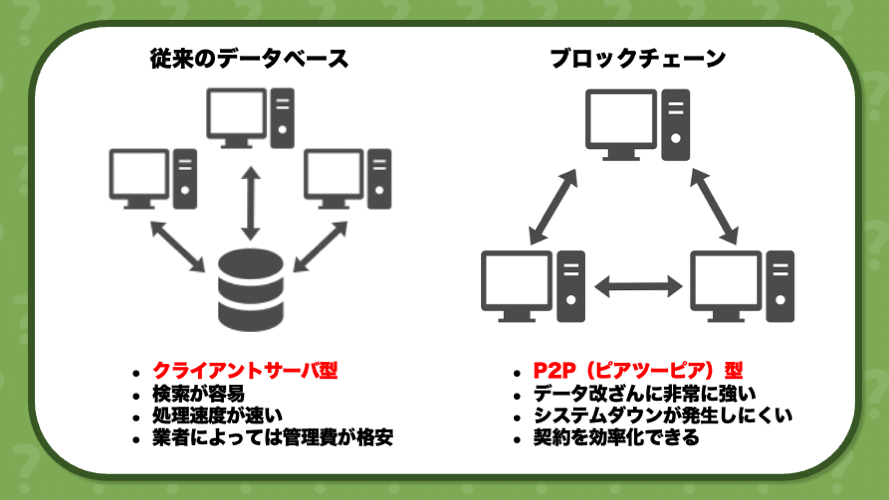
ブロックチェーンにおけるデータの保存・管理方法は、従来のデータベースとは大きく異なります。これまでの中央集権的なデータベースでは、全てのデータが中央のサーバーに保存される構造を持っていました。したがって、サーバー障害や通信障害によるサービス停止に弱く、ハッキングにあった場合に、大量のデータ流出やデータの整合性がとれなくなる可能性があります。
これに対し、ブロックチェーンは各ノード(ネットワークに参加するデバイスやコンピュータ)がデータのコピーを持ち、分散して保存します。そのため、サーバー障害が起こりにくく、通信障害が発生したとしても正常に稼働しているノードだけでトランザクション(取引)が進むので、システム全体が停止することがありません。また、データを管理している特定の機関が存在せず、権限が一箇所に集中していないので、ハッキングする場合には分散されたすべてのノードのデータにアクセスしなければいけません。そのため、外部からのハッキングに強いシステムといえます。
さらにブロックチェーンでは分散管理の他にも、ハッシュ値やナンスといった要素によっても高いセキュリティ性能を実現しています。
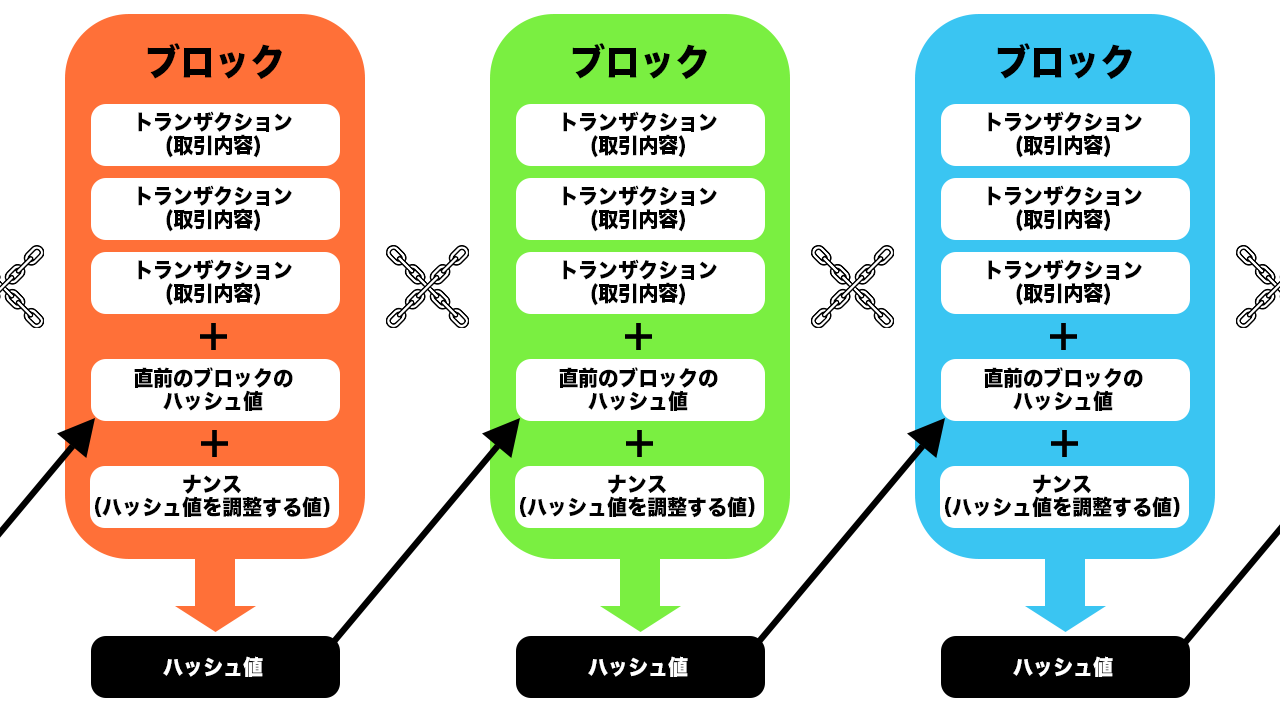
ハッシュ値は、ハッシュ関数というアルゴリズムによって元のデータから求められる、一方向にしか変換できない不規則な文字列です。あるデータを何度ハッシュ化しても同じハッシュ値しか得られず、少しでもデータが変われば、それまでにあった値とは異なるハッシュ値が生成されるようになっています。
新しいブロックを生成する際には必ず前のブロックのハッシュ値が記録されるため、誰かが改ざんを試みてハッシュ値が変わると、それ以降のブロックのハッシュ値も再計算して辻褄を合わせる必要があります。その再計算の最中も新しいブロックはどんどん追加されていくため、データを書き換えたり削除するのには、強力なマシンパワーやそれを支える電力が必要となり、現実的にはとても難しい仕組みとなっています。
また、ナンスは「number used once」の略で、特定のハッシュ値を生成するために使われる使い捨ての数値です。ブロックチェーンでは使い捨ての32ビットのナンス値に応じて、後続するブロックで使用するハッシュ値が変化します。コンピュータを使ってハッシュ関数にランダムなナンスを代入する計算を繰り返し、ある特定の条件を満たす正しいナンスを見つけ出す行為を「マイニング」といい、最初にマイニングを成功させた人に新しいブロックを追加する権利が与えられます。
ブロックチェーンではマイニングなどを通じてノード間で取引情報をチェックして承認するメカニズム(コンセンサスアルゴリズム)を持つことで、データベースのような管理者を介在せずに、データが共有できる仕組みを構築しています。参加者の立場がフラット(=非中央集権型)であるため、ブロックチェーンは別名「分散型台帳」とも呼ばれています。
こうしたブロックチェーンの「非中央集権性」によって、データの不正な書き換えや災害によるサーバーダウンなどに対する耐性が高く、安価なシステム利用コストやビザンチン耐性(欠陥のあるコンピュータがネットワーク上に一定数存在していてもシステム全体が正常に動き続ける)といったメリットが実現しています。データの安全性や安価なコストは、様々な分野でブロックチェーンが注目・活用されている理由だといえるでしょう。
詳しくは以下の記事でも解説しています。
これらの技術が結びつく交点=DX(デジタルトランスフォーメーション)

これまで長々と見てきたように、IoT、AI、ブロックチェーン、という3つの技術は、それぞれ異なる分野から生まれ、それぞれ独自の発展を遂げてきたものです。バラバラの文脈で語られることも多いIoT、ブロックチェーン、AIという3つの概念ですが、これらを単独で考えるだけでは、現代の技術が持つ本当の可能性を理解することは難しいでしょう。実は、この3つの技術は相互に補完し合う関係にあり、「ビッグデータ活用を前提としたDX」という結節点から分析することで、大きな社会動向の要素として相互に関連づけることができます。
例によって前提となるDX、ビッグデータについて解説します。日本デジタルトランスフォーメーション推進協会によると、DX(Digital Transformation、デジタルトランスフォーメーション)とは「ITの浸透が、人々の生活をあらゆる面でより良い方向に変化させる」という概念を指します。最近ではビジネスシーンでもよく耳にするこの単語ですが、実はDXとは、単にアナログデータをデジタル化(デジタイゼーション)するだけではなく、産業や社会構造全体をデジタル技術によって刷新し、新しい価値を創造する取り組みを意味しているのです。
その中核を担うのが、ビジネスや研究の現場に溢れている大量のデータ、いわゆる「ビッグデータ」の活用です。ビッグデータ活用の大きな流れとは、次の通りです。
- データを集める
- データを保存・管理する
- データを分析する
- データを活用する(社会実装する)
まず、ビッグデータを活用するには、そもそもデータ自体が十分に集まっている必要があります。一見、簡単なことのように思えますが、実は、世の中には機械による処理が可能な形のデータ(構造化データ)とそうではない形のデータ(非構造化データ)、そしてデータとしてすら認識されていない情報があり、構造化されたデータは全情報のごく一部でしかありません。したがって、ビッグデータを活用してDXを実現するためには、まずデータを構造化する、あるいは自然の情報をデータ化するといった、①データ収集の作業が重要になります。
次に、①で集めたデータを適切に保存・管理していく必要があります。実は、これもデータ分析を行なった経験がないと想像しにくいことですが、データ分析において自分の思ったような形で正しくデータが揃っているということはごく稀です。実際には、データの一部が欠損していたり、データそのものの信用が怪しかったり、異なるデータベース同士を接合する必要があったりと、いわゆる「データの前処理」という地味で根気の要る仕事が大半を占めています。これは、そもそも現時点では、多くの産業や企業においてデータを適切に管理するための基盤が整っていないことに起因しています。したがって、DXに向けて大量のデータを正しく活用していくためには、②データの保存・管理の方法が大切なのです。
続いて、あるデータベース上に保存されたデータを分析していきます。当然のことながら、データは集めて保存しているだけでは価値がありません。付加価値を出していくためには、情報の羅列であるデータベースから、何かしらの目的を持って分析を行い、実際の業務等に反映して効率化を実現していく必要があります。ですが、現実には、ビッグデータが重要であるということだけを鵜呑みにして「とにかくデータを集めろ」で終わっている企業も少なくありません。これは、先ほどもみたように、データを適切に取り扱える人材が不足していることにも原因がありますが、それ以上に、「データは分析して実際に役立ててナンボ」という当たり前の考え方が欠落しているからだといわざるを得ないでしょう。そのため、ビッグデータ活用によるDXでは、この③分析のフェーズを意識して全体を設計していくことが重要だといえます。
最後に、分析の結果であるモデルに当てはめて、現実世界の施策として社会実装していきます。一般に「ビッグデータ」「DX」というとこの社会実装の部分ばかりがケースとして目立ってしまいますが、実は、①〜③の流れを適切に行うことができていれば、半分はクリアしてしまったようなものです。もちろん、実際には、理論を現実へと実装していく過程が最も困難な場合がほとんどではありますが、そうした困難の原因として、目的から正しく逆算せずに「場当たり的に」データ活用を行おうとした結果、当事者が納得するような施策にまで十分落とし込めなかったということが少なくありません。そのため、④データの活用、社会実装を適切に遂行する上でも、①〜③の収集→管理→分析が大切だといえるでしょう。
このように分解してみると、精緻な顧客分析、需給予測の観点から「金のなる木」という見方をされることも多いビッグデータですが、データそのものは単体ではただのデータに過ぎず、それ自体が直接的な価値を持つわけではないということがおわかりいただけたのではないでしょうか?むしろ、膨大な情報が眠る「鉱山」のような存在だと捉える方が適切でしょう。
そして、この鉱山から金を生み出す各プロセスで大切な役割を担うのが、IoT、ブロックチェーン、AIという3つの技術です。IoTは鉱山の位置を特定して価値ある鉱石(データ)を発掘する役割を果たし、ブロックチェーンは採掘された鉱石が本物であることを保証し、AIはその鉱石を加工して価値を最大化する、といった具合にそれぞれの役割を果たしながら連携することで、初めてDXが実現するのです。
DXにおいてIoT、AI、ブロックチェーンはどのような役割を果たす?

IoT、AI、ブロックチェーン、そしてこれら3つの技術とDXとの関係性について大まかに把握したところで、それぞれが具体的にどのように作用し合い、ビッグデータの活用を支えているのかを掘り下げていきましょう。DXの中核をなすビッグデータの流れを見ていくことで、これらの技術が単独ではなく相互補完的に機能していることが明らかになるはずです。
先ほど見たビッグデータ活用によるDXの流れと、IoT、ブロックチェーン、AIの3概念は、それぞれ次のように対応させることができます。(※下記の対応は、必ずしも現時点でそうなっているとは限らず、今後の未来における一つの形を提唱しています)
- データを集める → IoTによるハードウェア端末でのデータ収集
- データを保存・管理する → ブロックチェーンによるデータベースの統合・管理
- データを分析する → AI(機械学習)による大量情報の処理
- データを活用する(社会実装する)
まず、IoTの役割は、私たちの日常に存在するあらゆるモノをインターネットにつなぎ、データを収集することです。これにより、身近な情報端末を通して、私たちの日々の行動パターンや好みをデータとして蓄積することが可能になります。たとえば、Amazon社の「Echo」シリーズやGoogle社の「Nest」シリーズに代表されるスマートスピーカーは、所有者が好む音楽、家族の声の波形、エアコンの設定温度といった多種多様なデータを取得しています。さらに、こうしたIoT技術は家庭内だけでなく、通勤経路や公共交通機関、オフィスビル、飲食店、学校、病院といった日常のあらゆる拠点で活用されるようになり、これまで活用されなかったデータの収集を可能にしています。
しかし、膨大なデータが収集されても、それを安全かつ効率的に管理する仕組みがなければ活用することはできません。現代社会では、数多くの企業がそれぞれ独自の端末やフォーマット、データ取得経路を用いてデータを収集し、それぞれの基準で管理しています。こうした分断されたデータベースでは、システム間でフォーマットが統一されておらず、データを横断的に活用することが困難です。また、セキュリティ要件が十分に担保されていない場合もあり、不正アクセスや改ざんといったリスクが潜在しています。このような状況では、ビッグデータを最大限に活用するための効率的なデータ統合が課題となります。
ここでブロックチェーンの技術が、DXを支えるための強力なソリューションとして機能します。ブロックチェーンは分散型の台帳技術に基づいており、改ざんがほぼ不可能なデータベースを構築できます。したがって、複数の企業が独立して管理しているデータを一元化し、異なるフォーマットや基準の間でも信頼性を持って統合することを可能にします。データの真正性も担保されることで、企業間を横断するようなデータのやり取りであっても、「〇〇社だけセキュリティ要件が満たされていない!」というような穴も生まれにくい構造になっており、IT部門・セキュリティ部門のYESも比較的取り付けやすいでしょう。世界経済フォーラムの試算によると、2025年までに世界のGDPの10%がブロックチェーン基盤上に乗るとされています。この予測は、ブロックチェーンが単なる技術革新にとどまらず、経済や社会全体の基盤としての地位を築く可能性を示しています。
最後に、ブロックチェーン基盤上で管理・統合されたデータを処理するのがAIの役割です。ビッグデータ、とりわけIoTで集められたデータ群は、これまでデータ分析の領域が取り扱ってきたものよりも変数が多く、モデルも複雑化します。こうしたデータを取り扱う上では、ディープラーニングを始めとした機械学習モデルが有効です。例えば、メーカーの大規模工場におけるDXのプロセスでは、各機械で計測されたセンサーデータをもとに、勾配ブースティングなどの機械学習モデルによる「異常検知」(機械の誤作動による不良品生産等のミスが起こる確率と条件をモデル化)を行うことで、工場のオートメーションを推進したり、無駄なコストを省くといった改善が試みられる、といった具合です。こうした分析は工場ライン一つ一つを具に見ていくだけではなく、全ラインを統合した形での全体分析を行う必要があり、まさに膨大な量のビッグデータを処理しなければなりません。AI(機械学習)は、こうしたデータ分析を実現する有効な手段といえます。
このように、IoT、ブロックチェーン、AIは、データの収集→管理→分析という一連の流れでそれぞれに長所を発揮しつつ、相互補完的な役割を果たす関連技術であると見ることができるのです。
DXでブロックチェーンが果たす重要な役割

先にみたデータの収集→管理→分析という一連の流れの中で、地味ながらも非常に重要な役割を果たしているのがブロックチェーンによるデータの管理です。ビッグデータを活用してDXを実現するということは、ある一企業や企業内の一部門だけで完結する類のプロジェクトではなく、産官学、サプライチェーンにおける川上と川下、同業他社、生産者と消費者など、異なる立場(そして時には敵対する立場)にいる複数のプレイヤー間での協業が不可欠になってきます。また、取り扱うデータの総量が大きくなるにつれ、関係する人の数やプロジェクトの期間も増え、オペレーションエラー等のリスクが高まっていきます。
しかし、その一方で、データ分析は非常に繊細な側面をもち、インプットするデータが少し変わるだけでアウトプットとなるモデルや仮説の精度が大きく左右されることも少なくありません。こうした前提条件のもとでは、複雑になりがちな管理をできる限りシンプルで、かつ、セキュリティ等のリスク要件を満たすような仕組みで解決できるような技術を採用する必要があります。ブロックチェーンは、こうした従来のデータベースでは解消が難しい複数の課題を解決しうるという点で、まさにDXにとってビッグデータを扱うのに打ってつけの技術なのです。
ここからは、ブロックチェーンの開発企業の目線から、ブロックチェーンの役割にズームしてDXを紐解いていきます。
ブロックチェーンの役割①:セキュアなデータ統合の仕組みを提供する
ビッグデータ利用にあたっての課題の一つに「データ統合」の問題があります。ビジネス上の価値があるデータは単体プレイヤーに閉じたものではなく、複数の異なるステークホルダーが持っているデータを統合した先にあります(例えば、口座のログイン情報は預金を引き出す上では金銭価値を持っている情報ともいえそうですが、ビジネスシーンではこうした情報は価値を持ちません)。
ここで問題となるのが、異なるデータベース間でのデータ共有における安全性の問題です。データベースが異なるということは、データを保存するフォーマットや構造化の方法、単位等、あらゆる要素が異なってきます。そうした諸データを統合することはそれ自体難度が高いばかりでなく、統合の際にデータを欠損する等のオペレーションエラーを誘発する原因にもなりえます。
さらに、仮にシステム上は統合が可能であったとしても、例えば競合関係にある複数社による統合が試みられるとした場合、誰が中心となって、どこまでのデータを、どういった権限のもとに共有するかという論点が生じます。こうした場合、各社が「もしかすると他社のいいようにやられて大切なデータまで取られるかもしれない・・」といった疑心暗鬼の状態に陥り、プロジェクト自体が頓挫してしまうケースも少なくありません。
こうした課題に対して、ブロックチェーンは極めて有効な解決策を提供します。ブロックチェーンは中央管理者を必要としない分散型の仕組みを持つため、データ管理の主体が特定の組織に偏ることなく、複数のプレイヤー間で透明性のあるデータ共有が可能です。すべての取引履歴やデータ変更は暗号化された上でチェーン状に記録されるため、不正や改ざんが事実上不可能になります。これにより、各ステークホルダーが「データの正確性」と「セキュリティ」に対する信頼を持ちながら、安心してデータ統合に参加できる環境が整います。
また、ブロックチェーンでは、データの一元化も効率的に実現されます。従来のように異なるデータベース間でデータを移動・変換する必要がなく、ブロックチェーン上で統一されたフォーマットのもと、直接的なデータ共有が可能となるため、統合の手間やオペレーションエラーのリスクが大幅に軽減されます。
例えば、サプライチェーン全体の効率化においては、生産者、物流業者、小売業者など、異なる立場にいる各プレイヤーが同じブロックチェーン上でデータを共有することで、リアルタイムの情報共有と透明性の確保が実現します。これにより、在庫管理の最適化や無駄の削減、トレーサビリティの確保といった課題を効果的に解決できるのです。
実例として、NTTデータが提供する「バッテリートレーサビリティプラットフォーム」が挙げられます。このプラットフォームは、業界全体でのカーボンニュートラル達成や資源循環型社会の実現を目指し、電動車向けバッテリーの製造から廃棄、再利用に至るまでのデータを統合的に管理・活用する基盤を提供しています。ブロックチェーン技術を活用して異なる企業間でデータの共有や連携を安全かつ効率的に行うことで、カーボンフットプリントの管理やデータ主権の確保、スマートコントラクトによる効率的な運用が可能となっている点が特徴です。
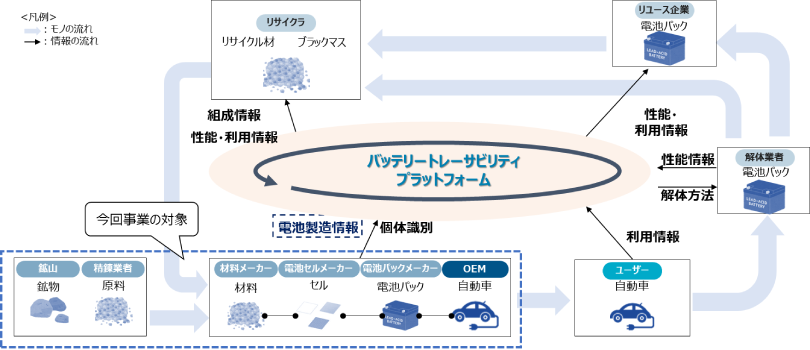
この仕組みは、欧州連合(EU)の新しい規則である「電池規則」にも対応しています。この規則では、2027年以降のバッテリー販売において、ライフサイクル全体でのCO₂排出量の算出と開示が義務化され、さらに再生原料の利用率や適正処理の証明などが求められます。NTTデータは、日本政府主導で2023年に設立された、ブロックチェーン基盤で規制対応や産業競争力の向上を目指すコンソーシアム「ウラノス(URANOS)」にも参画しており、同プラットフォームを通じてバッテリーのトレーサビリティやサプライチェーン全体の脱炭素化を支援しています。
今回のNTTデータの取り組みはまさに、利害関係が複雑に絡み合う異なるステークホルダー間でデータ統合を行なっていくことの可能性を示しているといえるでしょう。このように、ブロックチェーンは、「セキュアなデータ統合の仕組みを提供する」という重要な役割を果たしています。
ブロックチェーンの役割②:データの真正性を担保する
ビッグデータ利用にあたっての別の課題として、「データの真正性」の問題も発生しています。データの真正性とは、「取り扱うデータが欠損や改ざん等の欠陥のない正しいものかどうか」を表す概念です。先述したように、データ分析の精度を大きく左右するのは、実は分析そのもの以上に、データの真正性であるとされています。なぜなら、AIではデータをインプットとして関数を組み、精度の高いモデルを生み出すことを目的としているため、インプットであるデータが間違っていたら、当然、結果も間違ったものができてしまうからです。そのため、データ分析の世界においては、データ自体の真正性をなんとか担保する試みとして「データの前処理」という工程が最も重要視されています。
一方で、取り扱うデータの総量や関わる人間の数、プロジェクトの予算等が大きくなればなるほど、何かしらのヒューマンエラーであったり、悪意のある第三者によるデータ改ざんの攻撃を受けやすくなります。データの前処理では、ある程度の欠損等には対応しうるものの、データの真正性自体を正確に担保することはできません。したがって、収集したデータを管理する時点で、改ざん等のリスクを減らす仕組みを導入する必要が出てくるのです。
こうした課題に対してブロックチェーンでは、先述のハッシュ値やナンスを用いたデータ管理や、個々のデータ履歴自体へのセキュリティ(秘密鍵暗号方式)、コンセンサスアルゴリズムと呼ばれる合意形成のルールといった複数の仕組みによってデータを分散管理し、すべての取引履歴が暗号化された状態で記録されます。このデータは一度記録されると改ざんがほぼ不可能であり、誰がどのタイミングでデータを書き込んだのか、その履歴がすべて残る仕組みになっています。これにより、データの透明性と信頼性が高まり、複数の企業や組織が同じデータ基盤を参照する場合でも、データの真正性について疑う余地がなくなります。
例えば、食品産業においては、農場から加工工場、物流、そして店舗に至るまでのすべての流通プロセスをブロックチェーン上で記録することで、製品のトレーサビリティが担保されます。消費者は商品に付与されたQRコードをスキャンするだけで、その製品がどこで作られ、どのように流通してきたのかを簡単に確認できるようになります。この透明性は、食品安全の確保や企業の信頼性向上に大きく貢献します。同様に、医療業界では患者の診療データや治療履歴を安全に共有することで、医療機関同士の連携がスムーズになり、適切な診断や治療が迅速に行われる環境が整備されるでしょう。
ブロックチェーンによるデータの真正性担保の実例として挙げられるのが、旭化成とTISが共同開発した偽造防止ソリューション「Akliteia(アクリティア)」です。このソリューションは、旭化成が開発したサブミクロン(0.001mm以下)解像度の特殊パターンを印刷した透明な偽造防止ラベルを真贋判定デバイスでスキャンすることで、作品や鑑定書の真正性を確認することができるというものです。
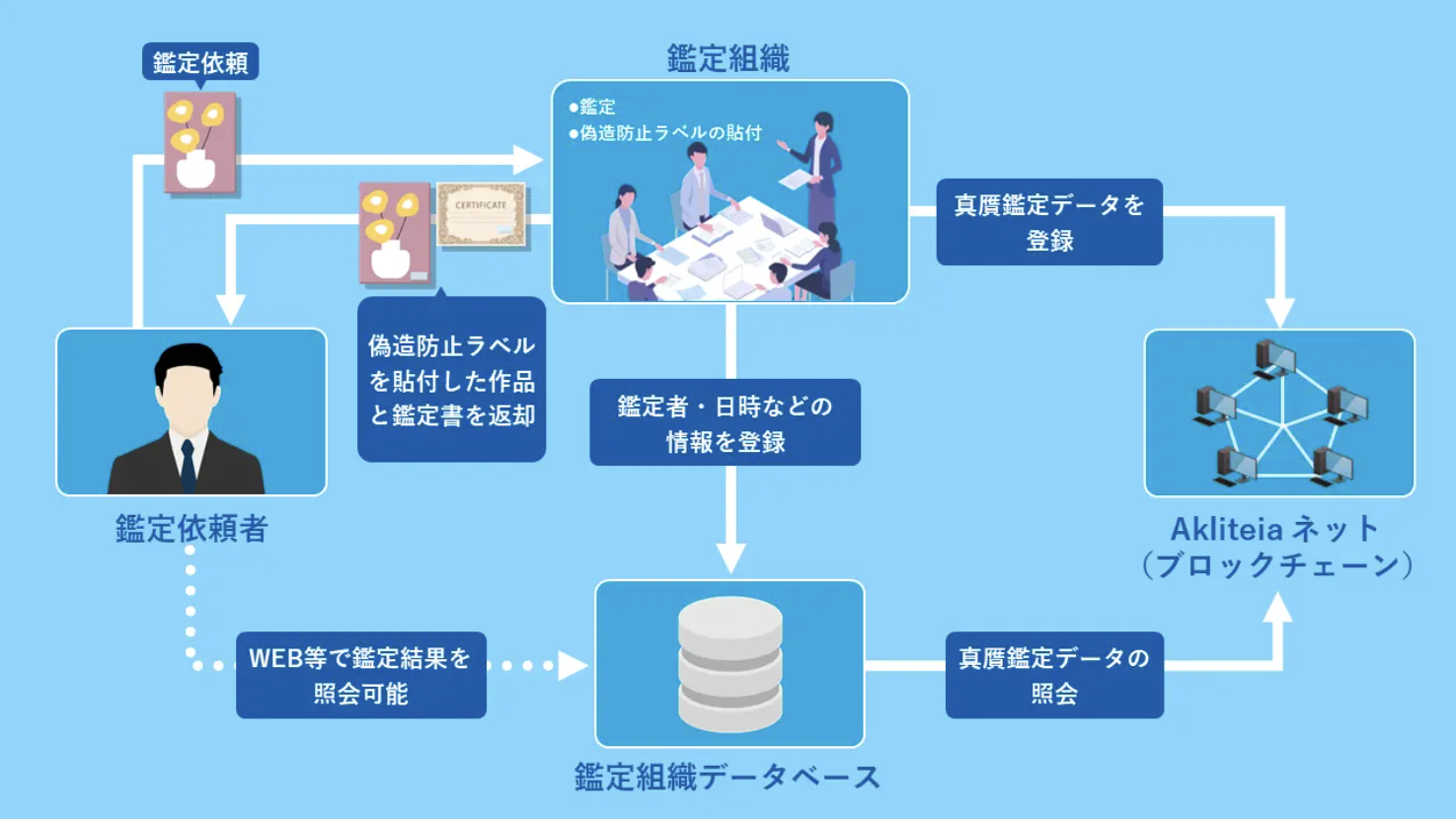
このスキャンデータは、TISがブロックチェーンプラットフォーム「Corda」を活用して構築したクラウドサービス「Akliteiaネット」に記録されるため、改ざんが不可能な形で情報が保存されます。データの真正性が特に要求される美術品の真贋判定にも用いられており、棟方志功作品の鑑定を行う「棟方志功鑑定登録委員会」では、偽造や贋作への転用リスクが高い従来の紙の鑑定書から同システムに乗り換えたことで、作品損傷や過去の鑑定履歴の管理、偽造品の発生状況をサプライチェーン全体で確実に共有することが可能になりました。サプライチェーン全体で偽造品発生状況を共有することで、被害の定量的な把握や可視化も可能となるため、どの段階で偽造品が多く混入されたかなど、被害実態の定量的な把握・可視化が行えるようになります。Akliteiaは、美術品分野に限らず、他の業界における製品の真正性担保やサプライチェーンの信頼性向上にも応用可能なソリューションとして、ブロックチェーンの実用性を示す一例です。
このように、ブロックチェーンは単にデータを保存する技術ではなく、その真正性や信頼性を担保する仕組みとして、ビッグデータ活用における「根幹」を支える役割を果たしています。DXにおいては、データを「ただ集める」だけでなく、そのデータがいかに正しく信頼できるものであるかが問われる時代です。ブロックチェーンの導入は、企業や組織間の信頼を築き、DXのプロジェクトを確実に推進するための基盤になるといえるでしょう。
ブロックチェーンの役割③:フィジタルな価値を創出する
DXが目指す変革の本質は、単なる効率化や業務改善にとどまらず、デジタル技術によって「新たな価値」を社会に創出することにあります。DXの提唱者であるエリック・ストルターマン教授によると、DXでは「美的価値」が中心的コンセプトとして位置づけられており、物理的な世界(フィジカル)と心理的・感情的な世界(メンタル)がデジタルが融合することで、いかに「フィジタル(フィジカル+メンタル)」な価値をユーザー体験として提供していくかという点にも触れられています。ブロックチェーンを活用したDXでは、NFT(Non-Fungible Token)がその鍵を握っています。
NFTとは、デジタルデータに唯一無二の「本物」としての価値を付与し、所有権や取引履歴を証明できる仕組みです。従来、デジタルデータは簡単にコピー・改変できることから、希少性や真正性を確立することが難しいとされていました。しかし、ブロックチェーン技術によるNFTは、データの改ざんが不可能であること、所有者や取引履歴がすべて暗号化されて記録されることから、デジタルデータに「唯一性」と「真正性」を付与し、信頼できる資産としての価値を生み出すことができます。
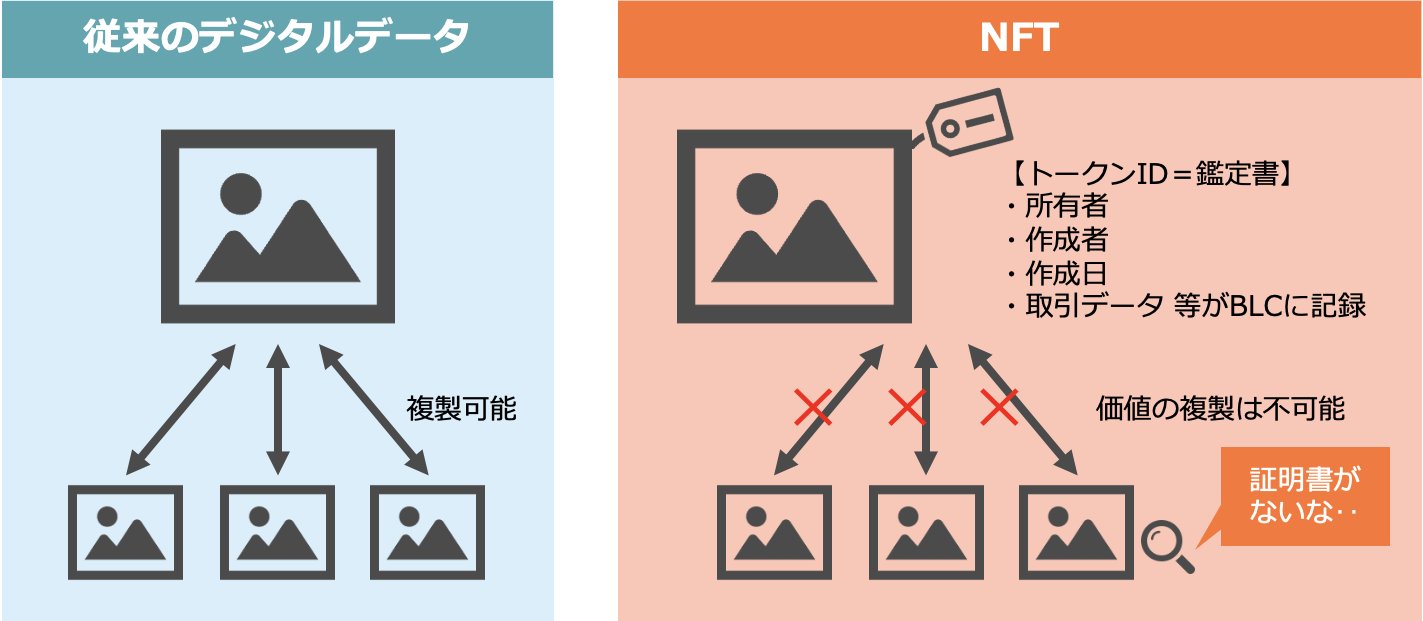
こうしたNFTの持つ特性は、現代のDXが求める「共感」「応援」「参加」「共同」という新しい社会的価値の創出と重なります。例えば、アート作品や音楽、ゲーム内のアイテムがNFT化されることで、アーティストやクリエイターとファンが直接つながり、そのつながりを通じて新しい経済圏やコミュニティが生まれています。デジタル空間で手に入れたNFTは、単なる所有物ではなく、「本物」に触れる喜びや、クリエイターを応援するという心理的な価値も含んでいます。これは、DXが追求する新たな体験価値の創出に他なりません。
NFTによる新たな価値提供の事例としては、NBA Top Shotが挙げられます。NBA Top Shotは、アメリカのプロバスケットボールリーグであるNBAの試合中の名場面を「モーメント」としてNFT化し、ファンがこれを購入、収集、取引できるプラットフォームです。このサービスはDapper Labsが開発したブロックチェーン「Flow」を基盤としており、高速かつ手軽な取引が可能で、これまでにない形でバスケットボールの魅力をデジタル空間に広げています。
NBA Top Shotでは、各モーメントがNFTとしての唯一性を持つため、収集家たちは自分のコレクションに希少性を見出し、その所有権を他者に証明することができます。ファンはお気に入りの選手やプレーのNFTを所有することで、単なる映像データを超えた「価値」を体感できるのです。また、取引市場がプラットフォーム内に整備されているため、NFTの売買を通じてコレクター同士の交流が生まれるなど、新しい形のコミュニティも形成されています。たとえば、ある名場面のNFTが高額で取引されるケースでは、バスケットボールファンの間でそのプレーや選手に対する注目が高まり、物理的なグッズとは異なる次元での「応援」が実現されています。
このように、ブロックチェーン技術を基盤とするNFTは、フィジカルとデジタルを融合した「フィジタル」な世界を具現化し、DXが掲げる「美的価値」や新たな体験価値の創出を支える役割を果たしています。ユーザーサイドに喚起される共感やつながりの意識、そして「本物」に触れる喜びは、デジタル技術が単なる効率化ツールではなく、人々の生活や社会を豊かに変革するための手段であることを示しているのです。
まとめ
ビッグデータの分析・活用はIoTに対する鍵であり、本質です。ブロックチェーンはIoTの可能性を広げる技術の一つとして期待されており、今後さらに多様なIoTとブロックチェーンの組み合わせが生まれていくと思います。将来的に、ブロックチェーンとIoTがどのようなサービスに変化するのか、その動向に注目です。
トレードログ株式会社では、非金融分野のブロックチェーンに特化したサービスを展開しております。ブロックチェーンシステムの開発・運用だけでなく、上流工程である要件定義や設計フェーズから貴社のニーズに合わせた導入支援をおこなっております。
ブロックチェーン開発で課題をお持ちの企業様やDX化について何から効率化していけば良いのかお悩みの企業様は、ぜひ弊社にご相談ください。貴社に最適なソリューションをご提案いたします。